
jmeter
jmeter
缺点
1 | 缺点: |
基本使用
线程组
进 程: 正在运行的程序
线 程: 是进程中的执行线索
线程组: 进程中有许多线程,为了方便管理,可以对线程按照性质分组,分组的结果就是线程组
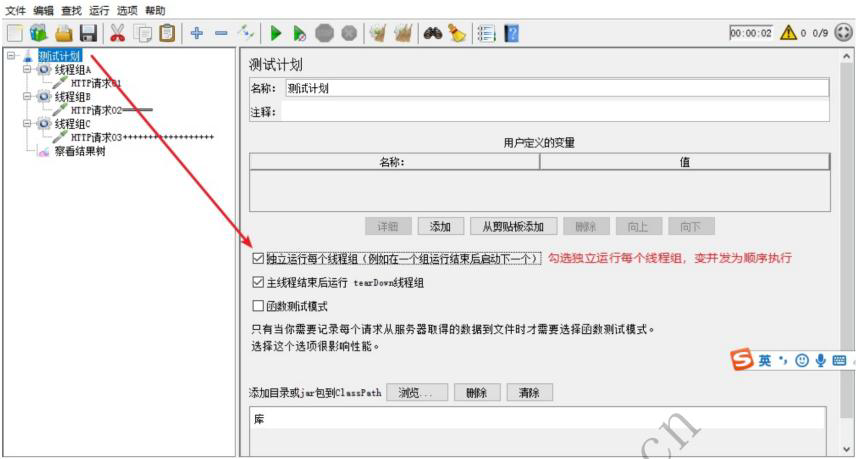
三者关系,一个进程可以包含多个线程组,一个线程组可以包含多个线程
并发执行
jmeter里俩个特殊的线程组
- setUp线程组:最优先执行的线程组
- tearDown线程组:最后执行的线程组
线程组常用属性
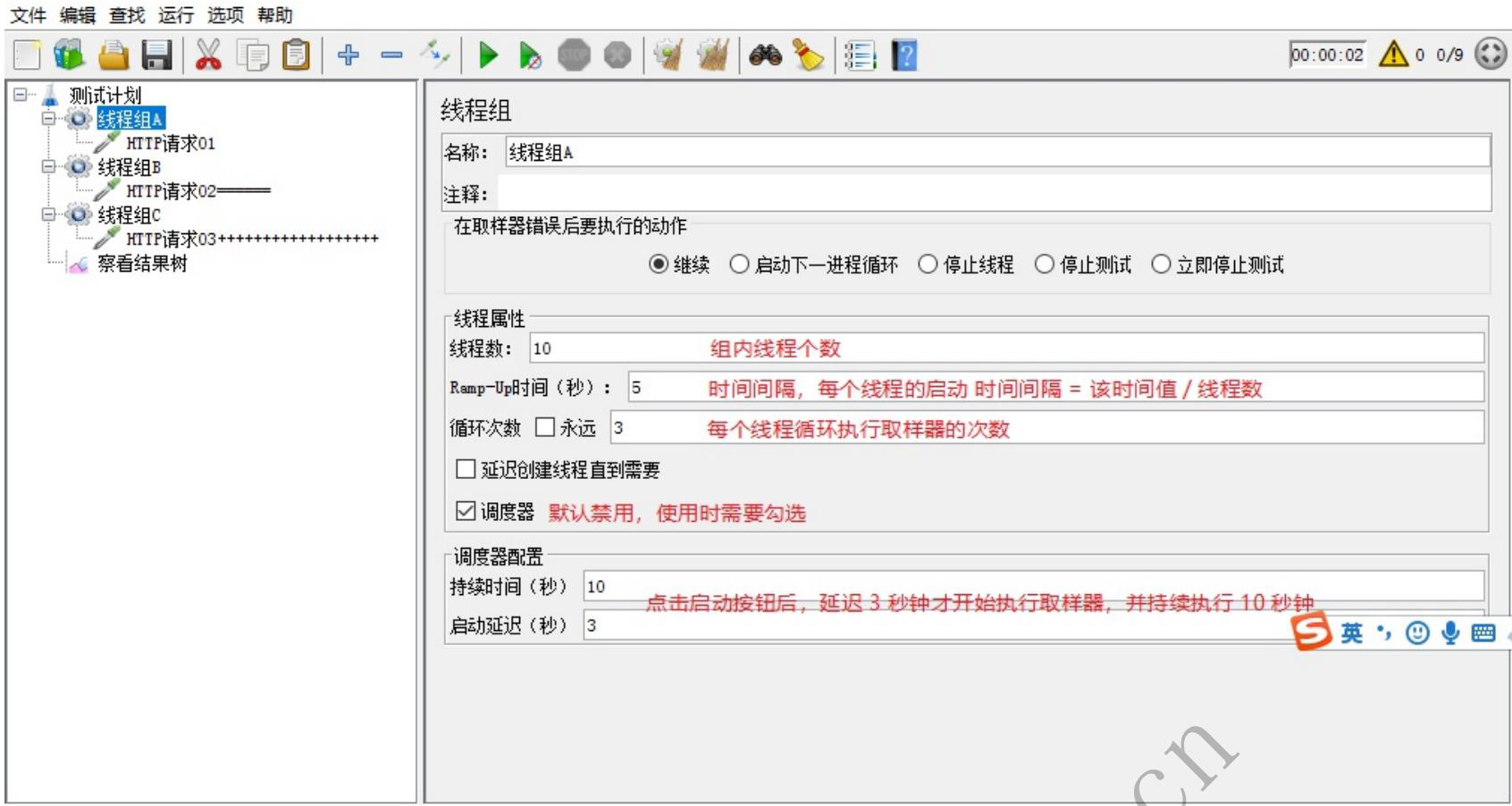
- 线程数:模拟的用户个数
- ramp:程序的准备时间
- 循环次数:每个线程执行的次数
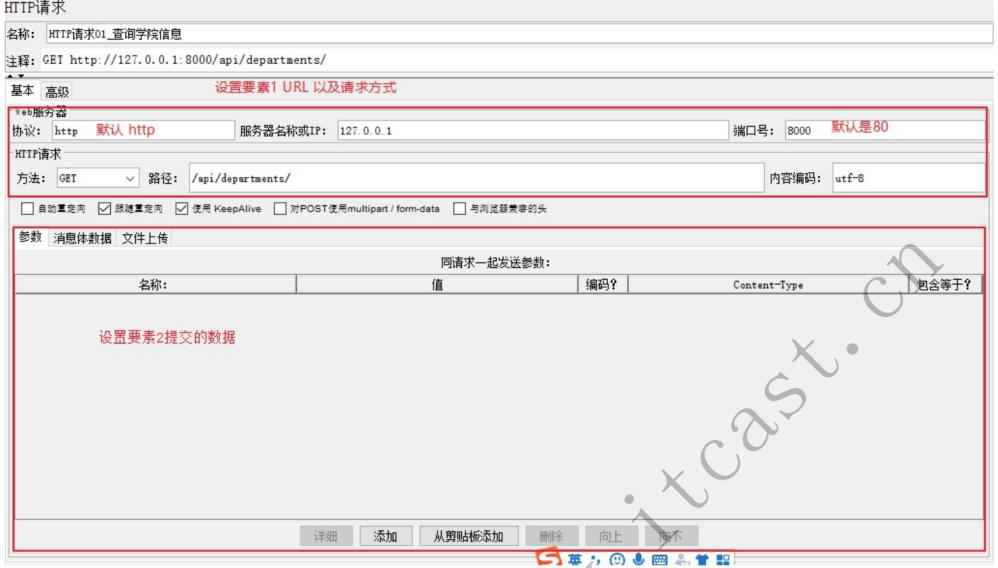
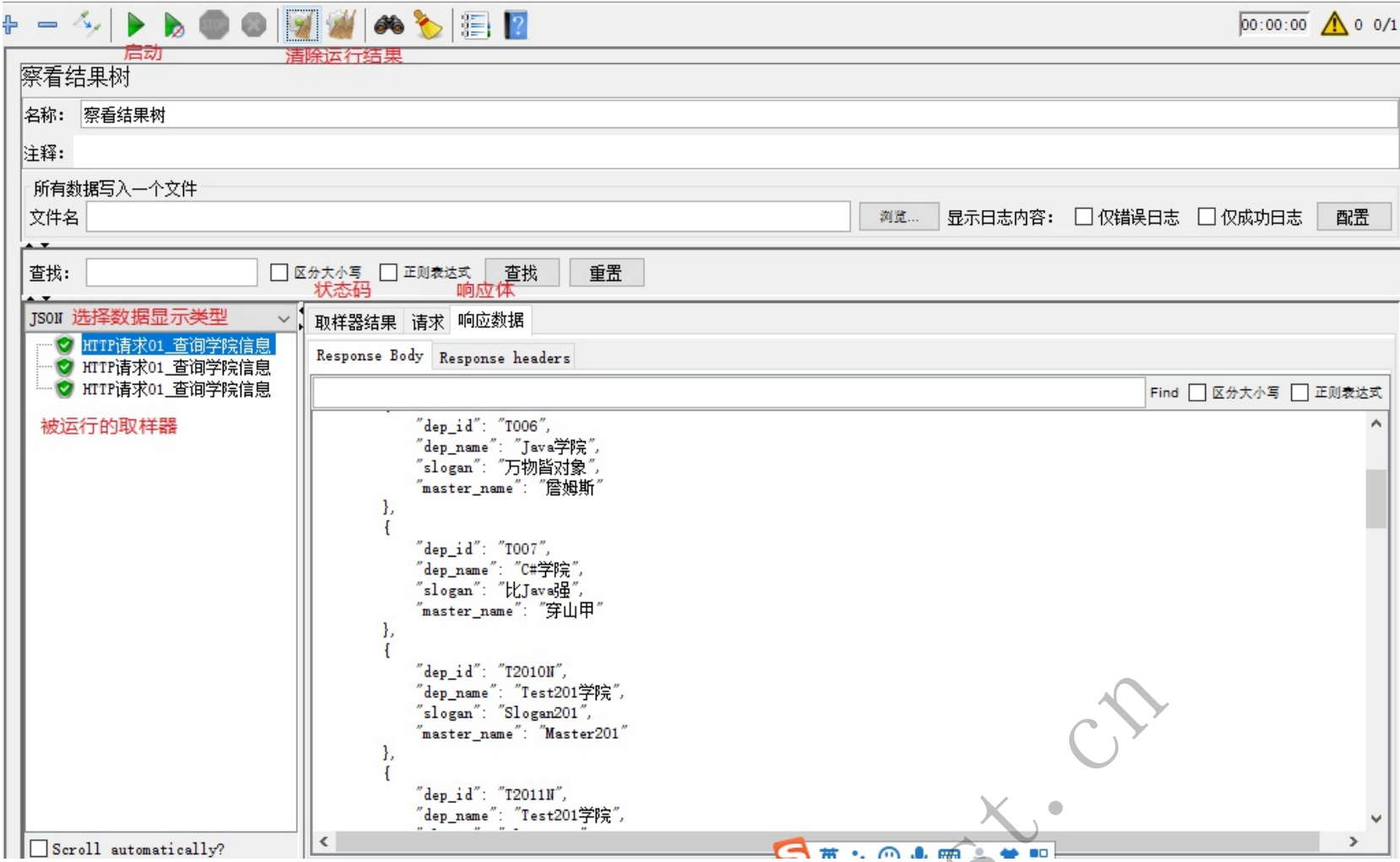
http请求默认值
http请求默认值:被复用的内容的封装
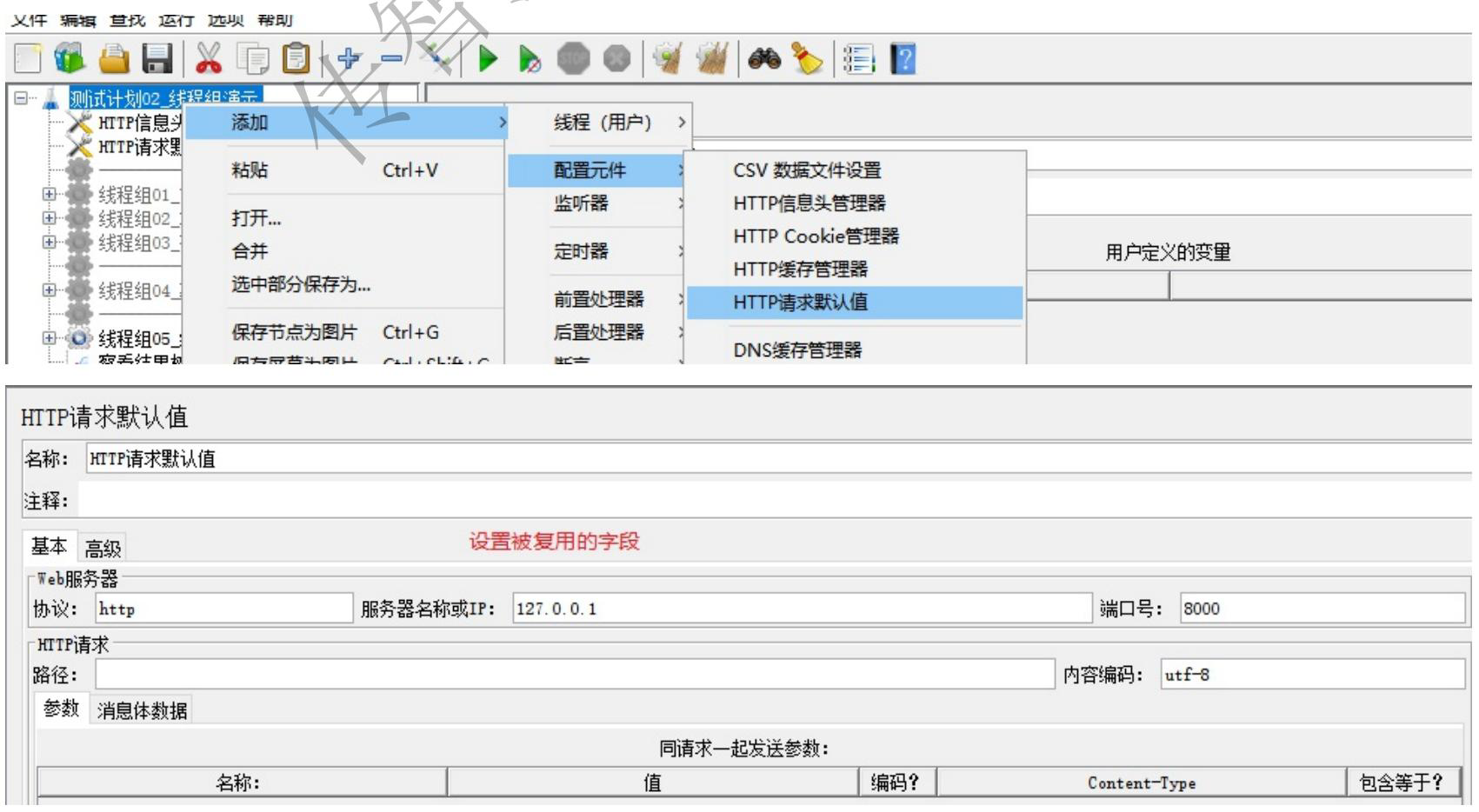
信息头管理器
新增修改实现时提交的数据是 JSON 格式的,需声明提交的数据的内容类型:
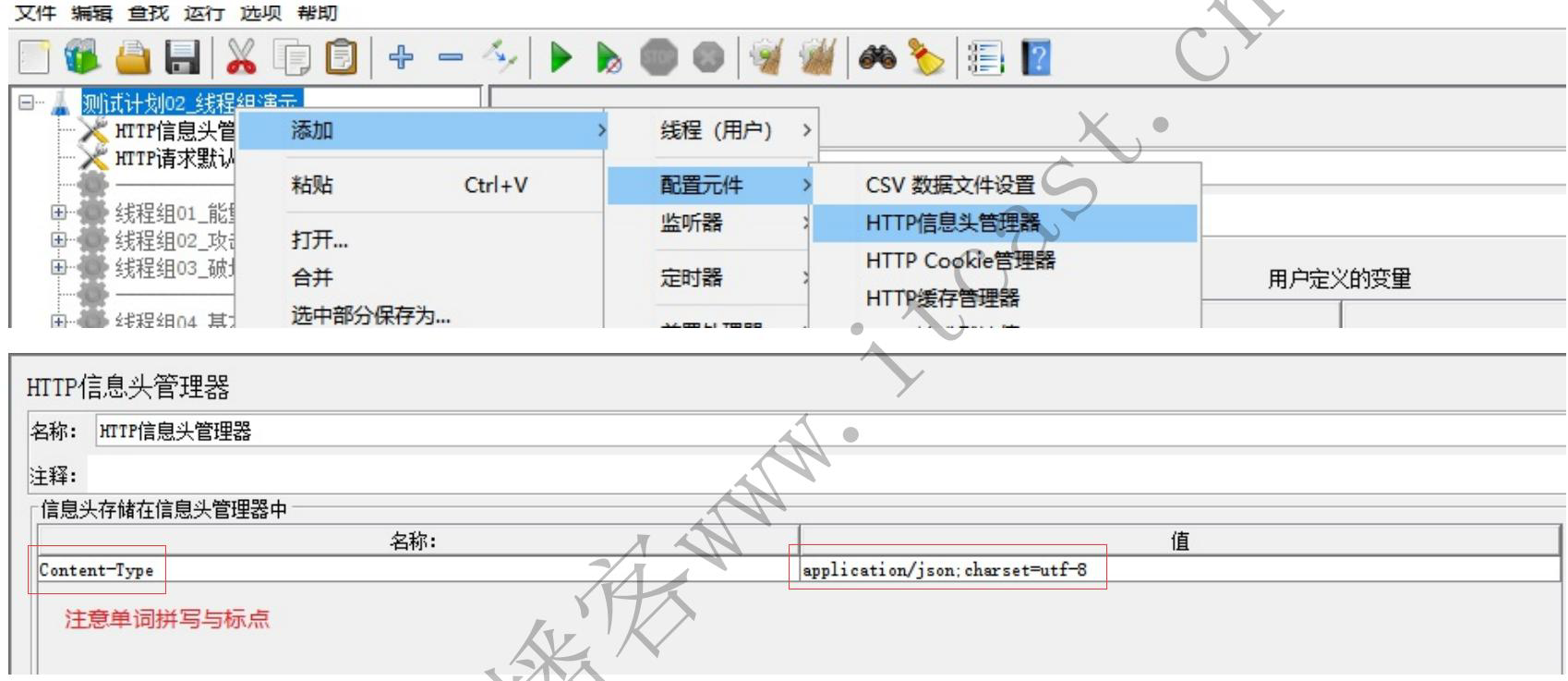
后端传数据的时候要在这声明提交的数据的内容类型才知道是json
参数化
定义:动态的获取、设置或生成数据,是一种由程序驱动代替人工驱动的数据设计方案,提高脚本的编写效率以及编写质量
以下四种方式实现参数化:
1、用户定义的变量
2、CSV 数据文件设置
3、用户参数
4、函数
参数化–用户定义的变量
调用格式: ${变量名}
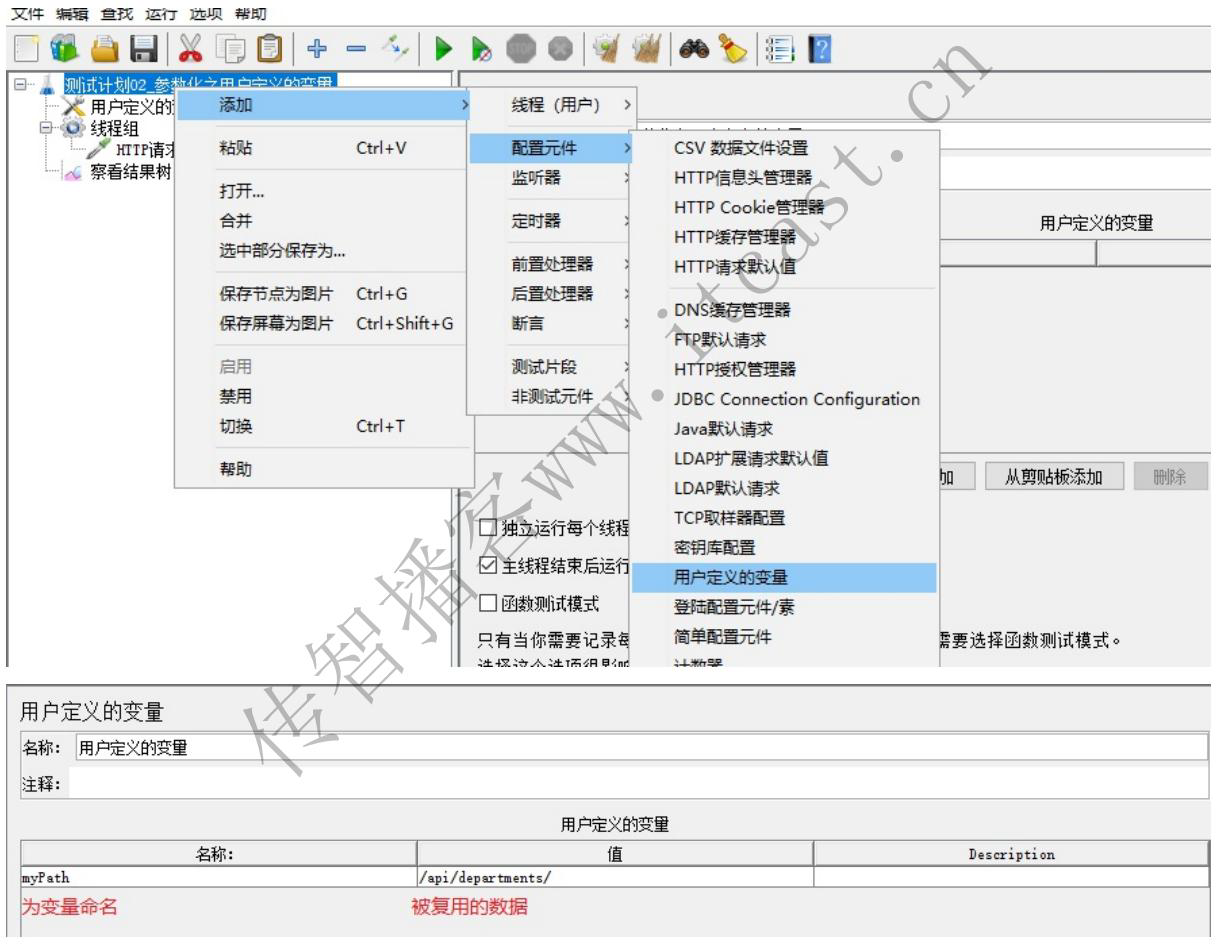
请求路径: {myPath}
参数化–CSV数据文件设置
CSV :逗号分隔值,是一种简洁且常见的数据存储格式,存储语法如下图所示
实现步骤:
1、使用 CSV 文件存储测试数据
2、编写被复用的学院新增脚本模板
注意2: 编码集使用 UTF-8 无 BOM 格式
3、关联脚本与数据(将文件数据导入脚本)
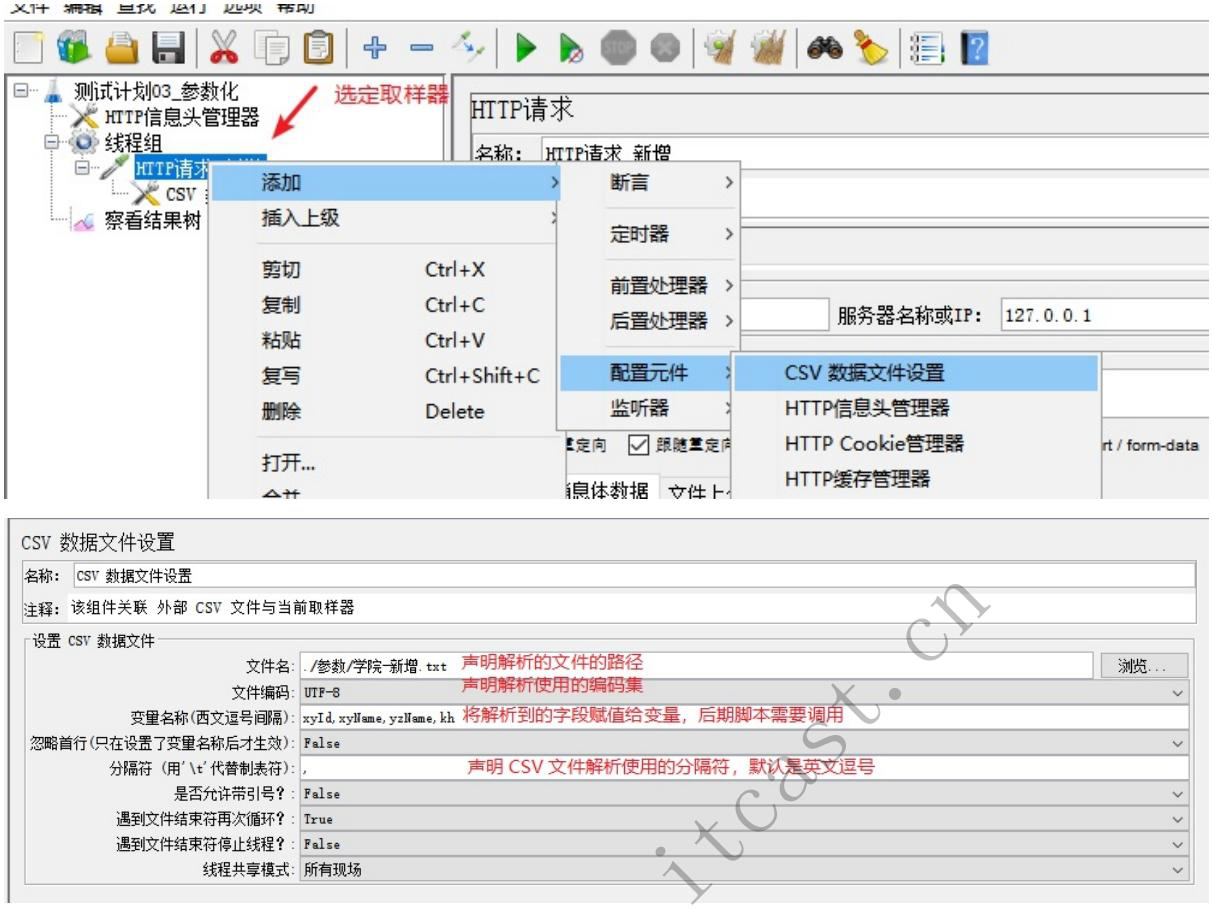
变量名称 : 脚本中的每个字段与变量名称相对应
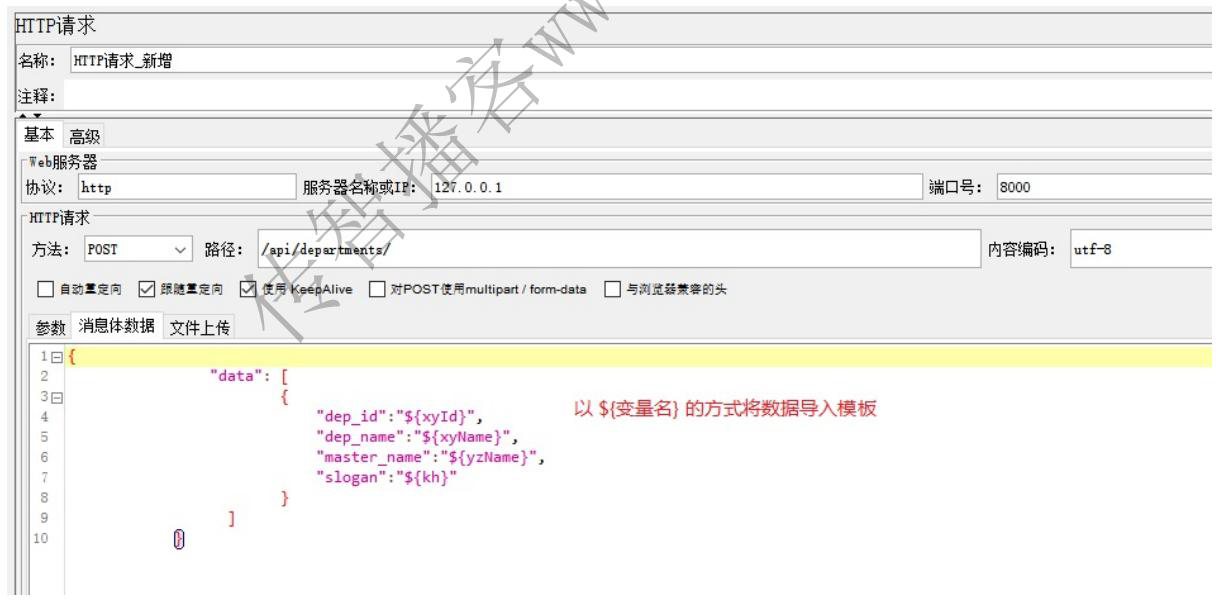
参数化–用户参数
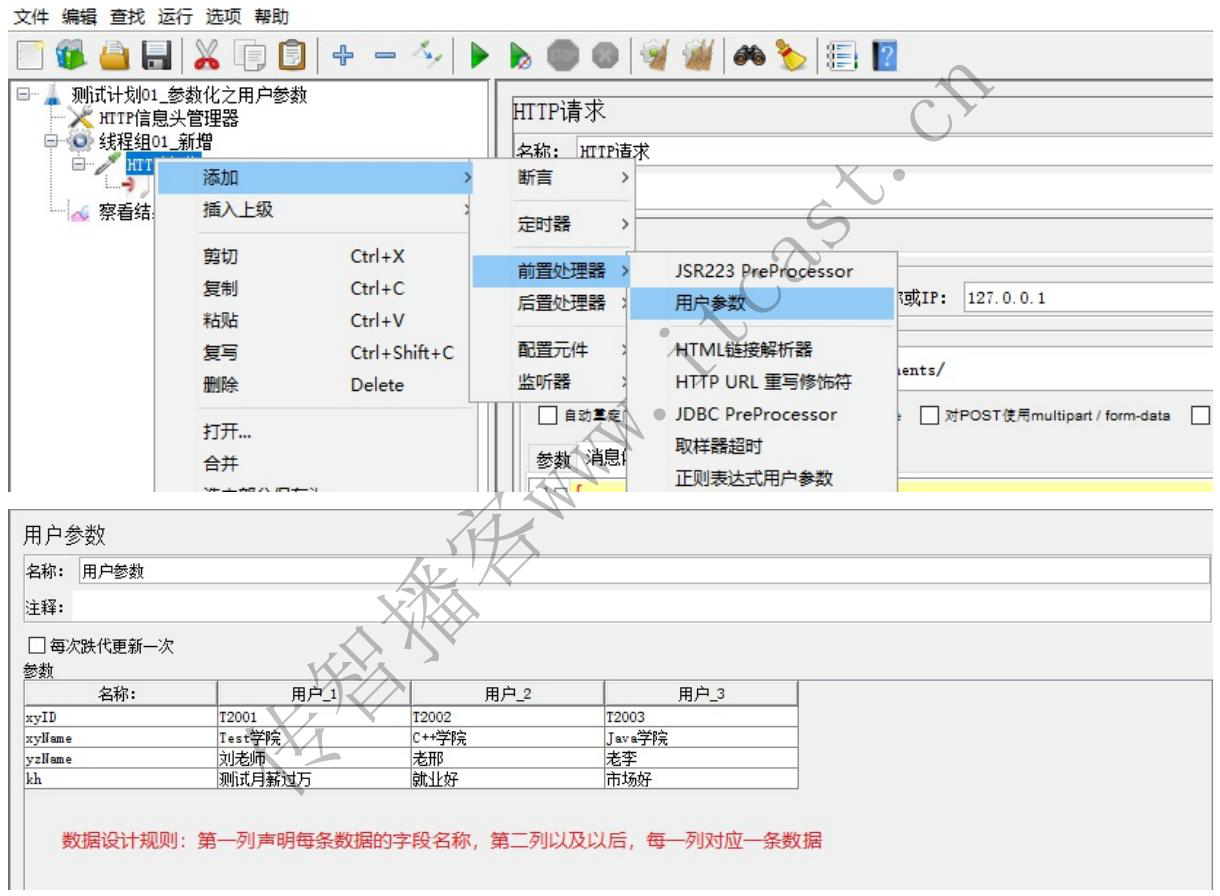
实现步骤:
1、编写被复用的学院新增脚本模板
2、使用 用户参数存储测试数据
3、将数据导入脚本模板
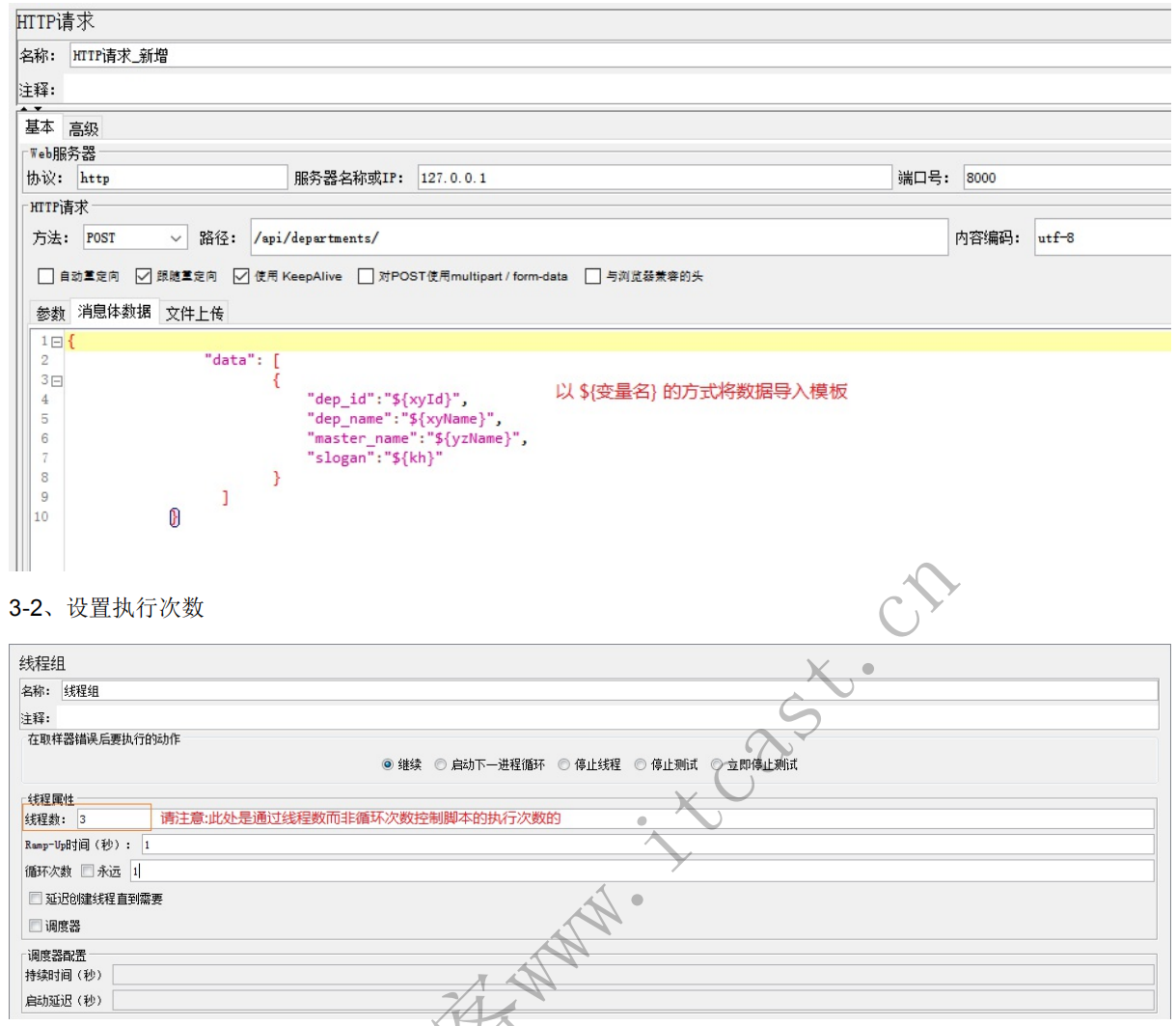
4、设置执行次数
参数化–函数
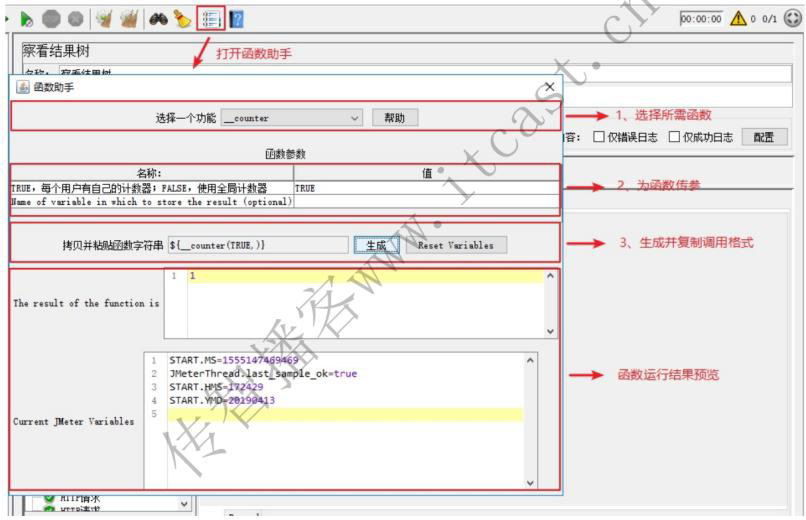
常见函数:
_counter 计数器函数 TRUE(每个用户都有自己的计数器) FALSE(所有用户共用一个计数器)
_Random 随机数函数 参数1:取值范围最小值(包含) 参数2:取值范围最大值(包含)
_time 获取当前时间的函数 无参: 获取的是距离 1970/01/01 00:00:00 的毫秒值
参数
直连数据库
通过直连数据库让程序代替接口访问数据库,如果二者预期结果不一致,就找到了程序缺陷。
获取某条学院的名字,放在百度搜索:
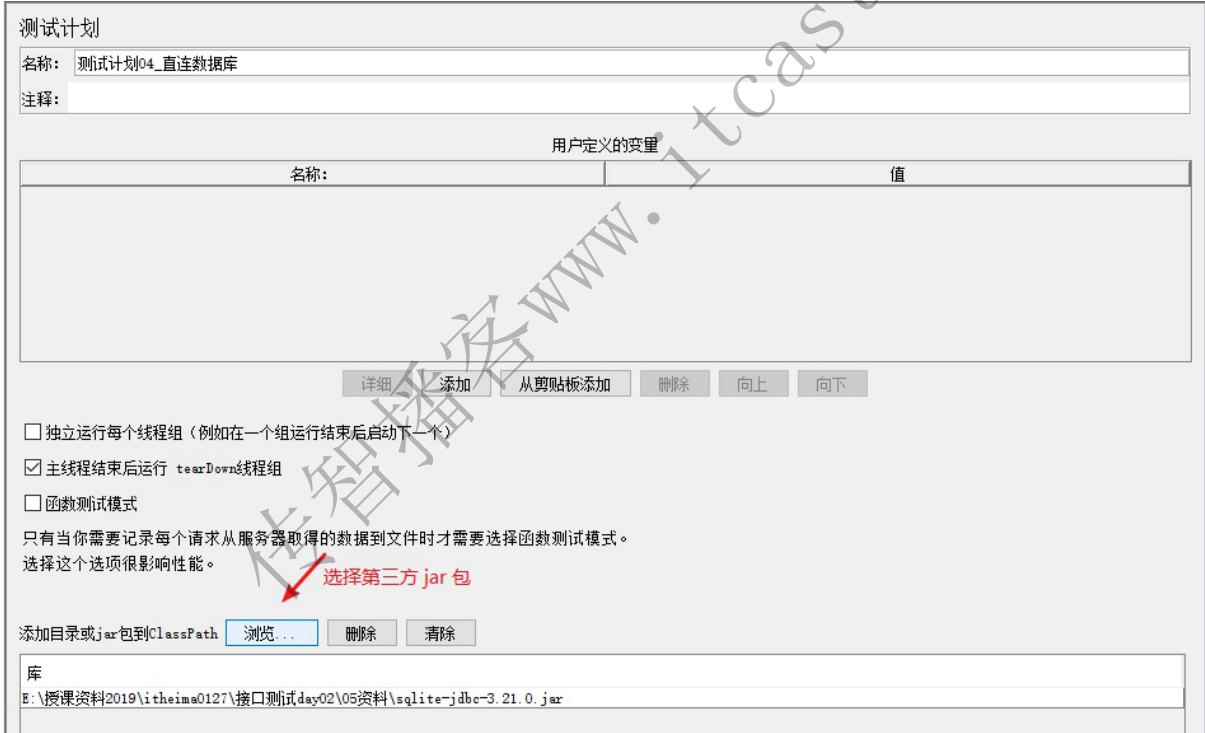
1、Jmeter 不具备直连数据库功能,必须整合第三方(jar包)实现
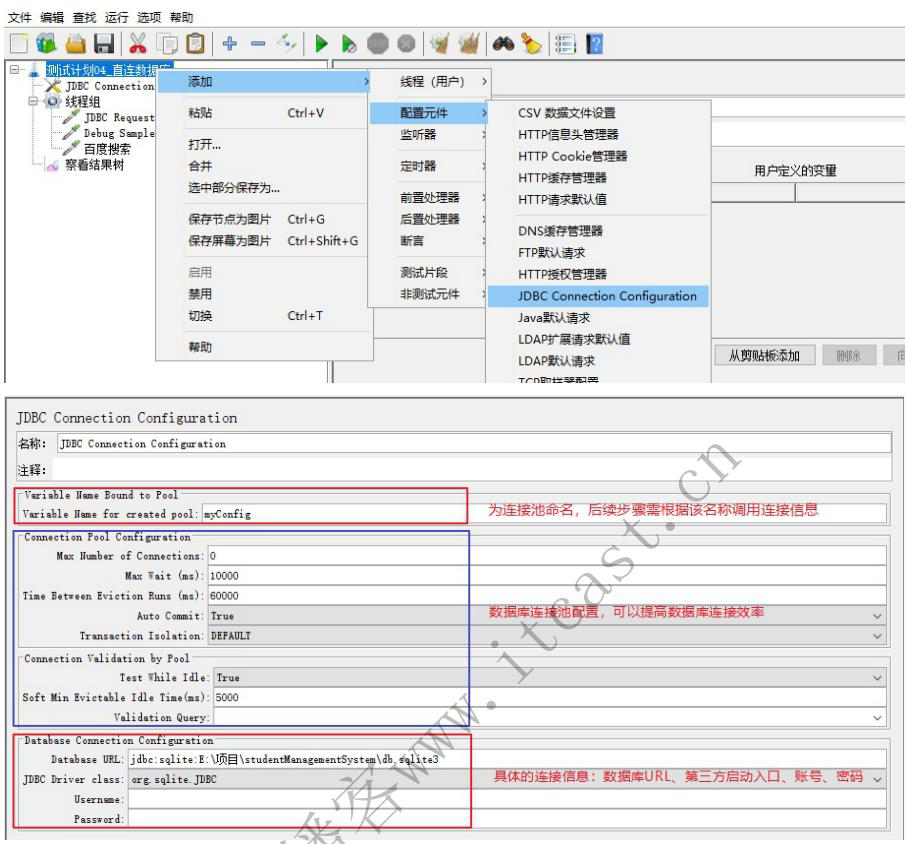
2、配置数据库的连接
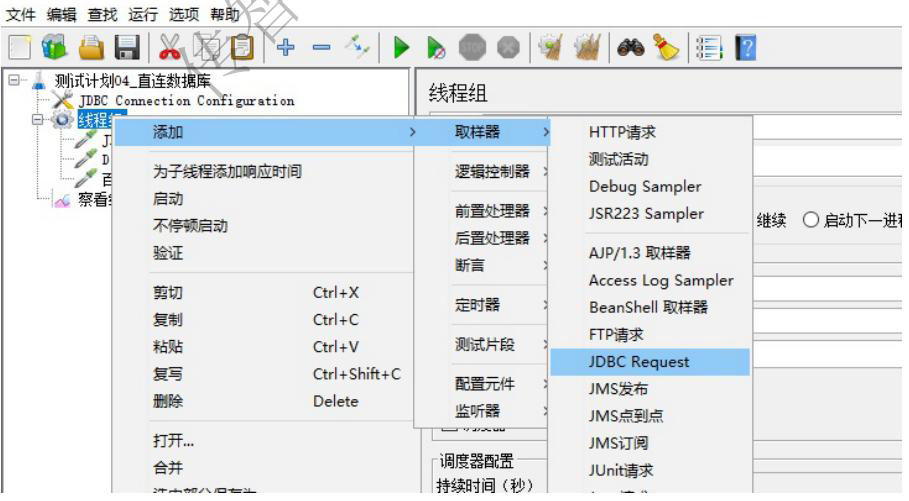
3、通过JDBC Request请求向数据库发送 SQL语句并接收提取响应结果
4、结果获取规则可以通过 Debug Sampler 组件查看
5、将提取到的响应结果,在百度上
- 添加jar包
- 配置数据库
- 编写sql语句
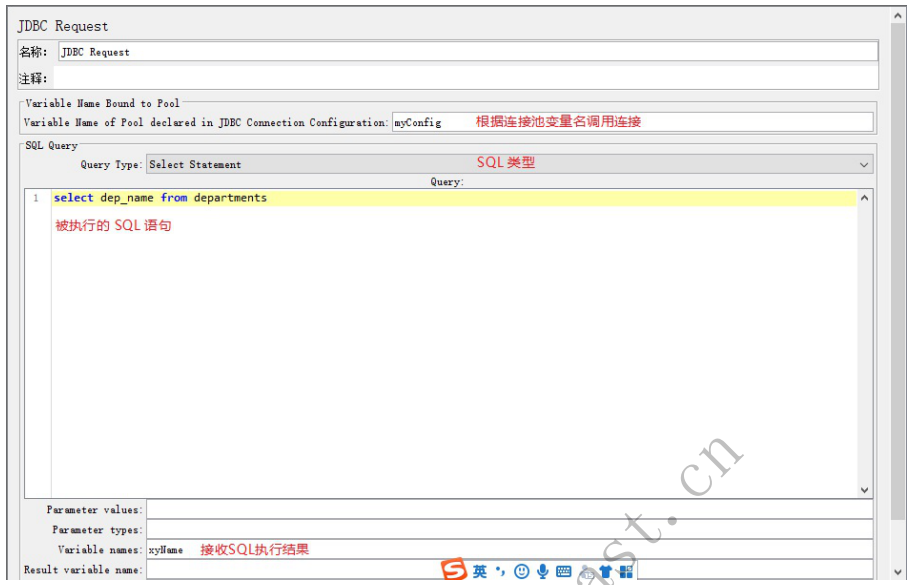
- 获取结果集通过Debug Sampler组件查看
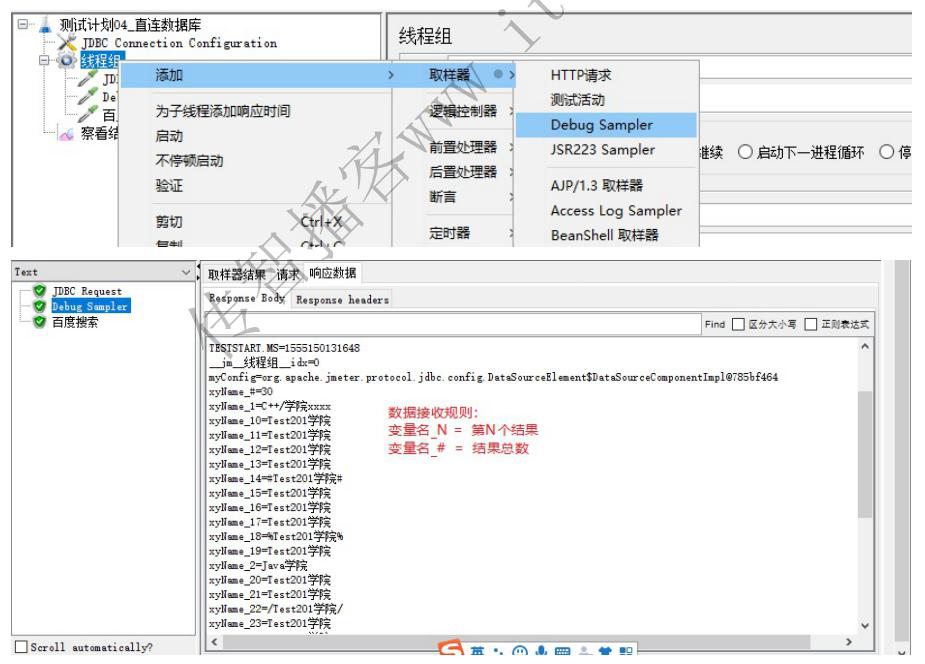
- 百度显示
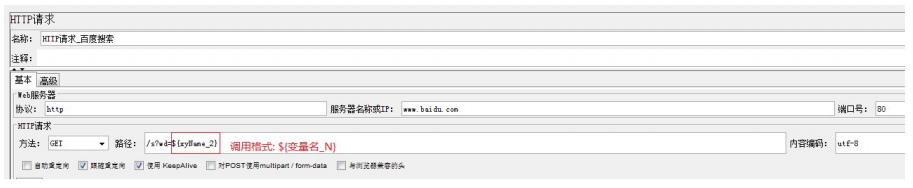
断言
断言:让程序代替人工判断响应结果是否符合预期
分类:
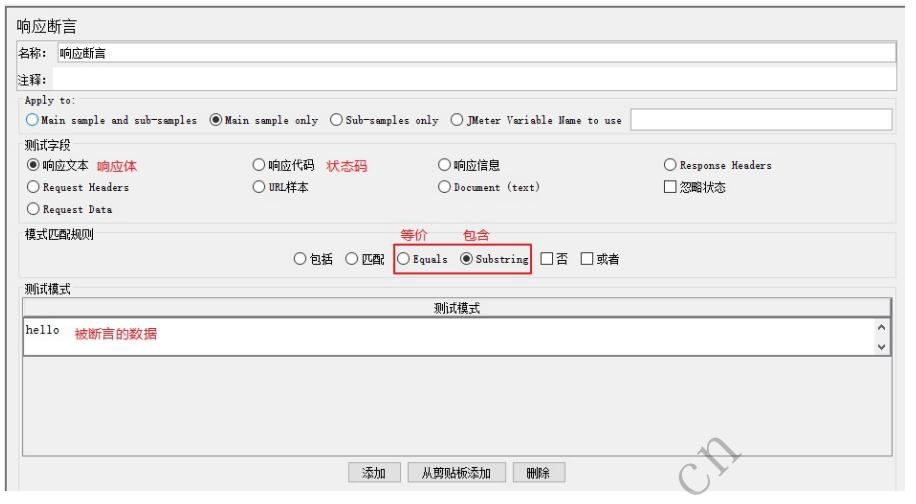
响应断言 = 断言状态码和响应体
大小断言 = 判断响应内容的字节长度
断言持续时间 = 判断响应时间
步骤:
- 1、按照之前的实现编写测试脚本
- 2、为被判断的取样器添加断言组件
- 3、直接运行查看结果断言通过: 无提示
- 断言失败: 给出错误
响应断言
大小断言
判断结果数据多少
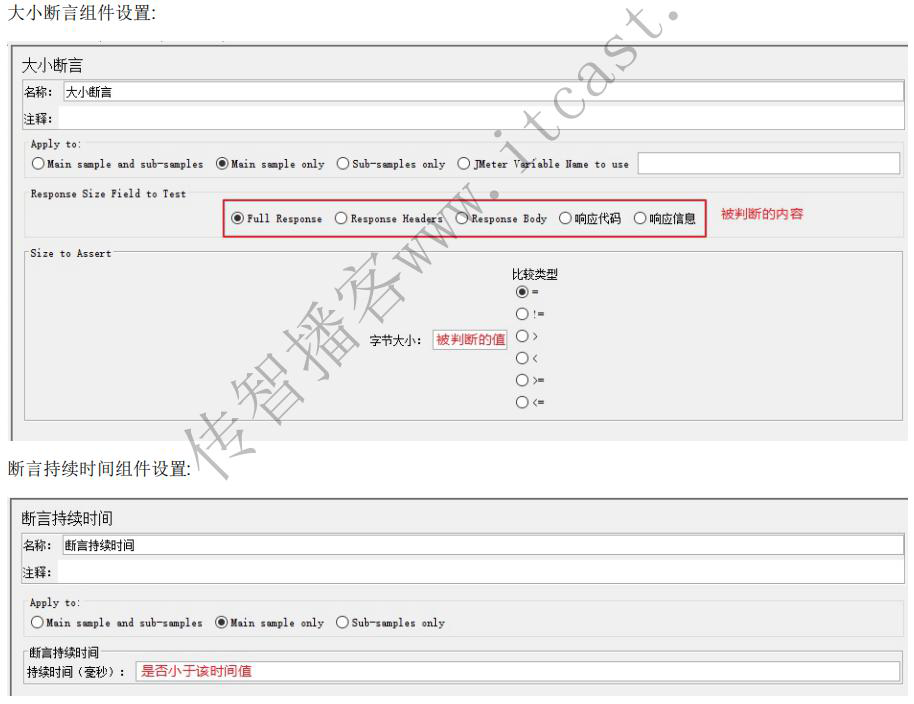
注:响应码是三个字节 !
逻辑控制器
通过参数化可以实现单个接口的功能测试,而接口测试过程中,除了单个接口的功能测试之外,还会测试接口业务实现,所谓业务,就是一套完整的业务逻辑或流程,这就必须要使用到逻辑控制和关联。
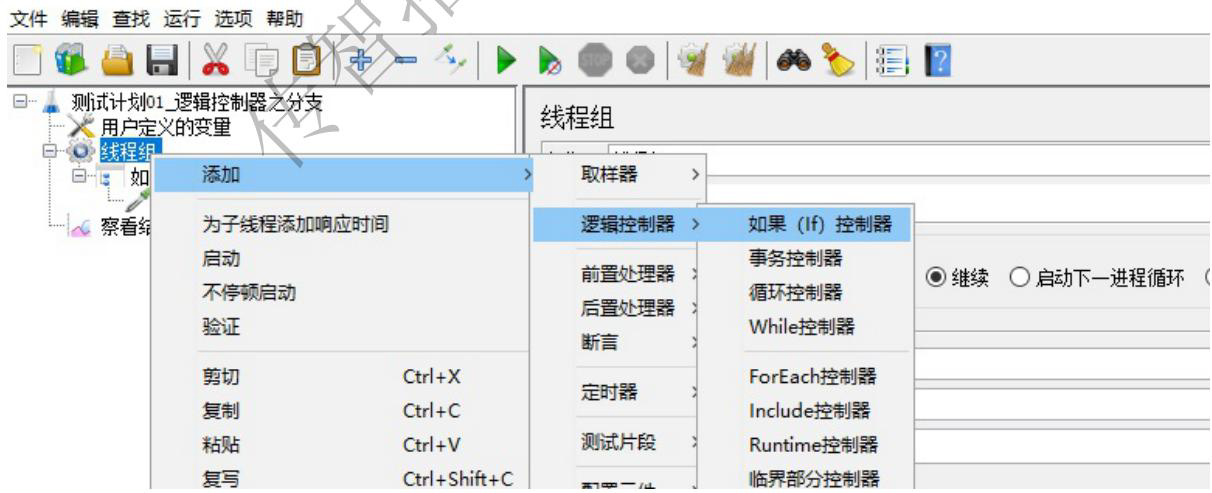
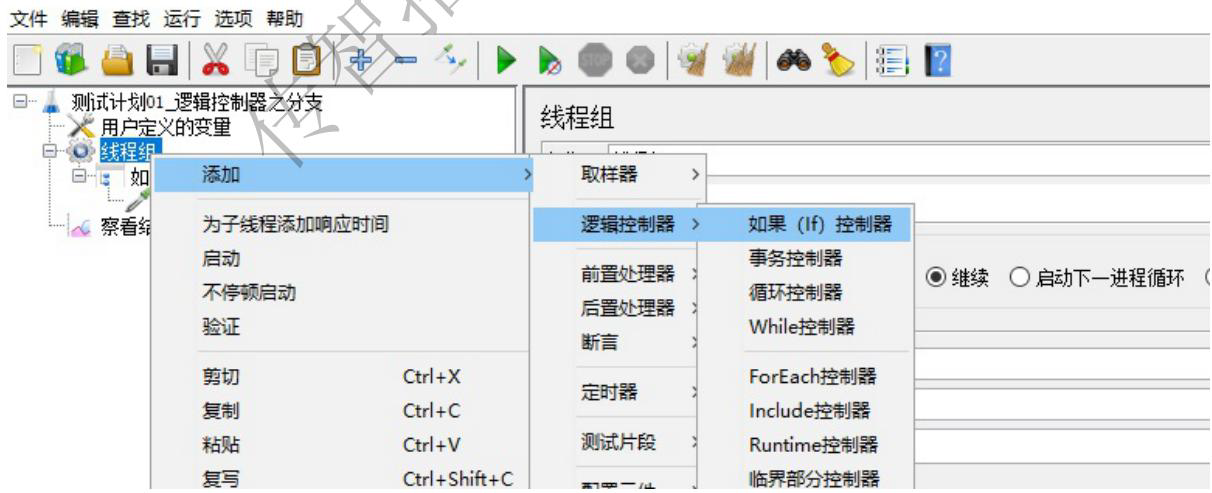
if逻辑控制器
需求1:测试计划中定义一个 http 请求访问传智播客官网,但是该请求不是无条件执行的,声明一个用户定义的变量,如果变量是 itcast 才执行,否则就不执行
1、搭框架,测试计划,线程组,结果树,声明一个用户定义的变量
2、核心:添加 if 控制器,子级添加取样器 (和之前实现不同,控制器和取样器存在父子级关系)

如果在用户定义变量中设置 名称为myComp值为 itcast 那么请求可以执行
foreach逻辑控制器
需求2:有一组关键字 [hello,python,测试] (使用用户定义的变量存储)要依次取出,并在百度搜索
1、搭框架,测试计划,线程组,结果树,声明一个用户定义的变量,存储一组数据
2、添加 forEach 控制器,子级添加取样器 (和之前实现不同,控制器和取样器存在父子级关系)
3、百度搜索关键字
配置原件中设置自定义变量
| 名称 | 值 |
|---|---|
| name_1 | java |
| name_2 | c |
| name_3 | py |

请求路径中含有${ele}
循环逻辑控制器
需求3:循环访问学生管理系统10次
实现:
1、搭框架,测试计划,线程组,结果树
2、添加循环控制器,子级添加取样器 (和之前实现不同,控制器和取样器存在父子级关系)
局部循环罢了

业务之间的关联
关联: 上一个请求的响应结果和下一个请求的数据有关系
比如,要删除数据要先查出来才能删除
关联-xpath提取器
获取标签内容
需求:两个http请求,请求A访问传智播客官网,请求B访问百度 ,请求A将传智播客官网源码中的 title 标签的值取出,传递给请求B,在请求B中作为关键字搜索这个 title 值
步骤:
1、搭框架,编写两个请求,传智播客 + 百度搜索
2、核心: 取出传智播客页面源码的 title 值
3、传递给百度:${变量名} 的方式传值
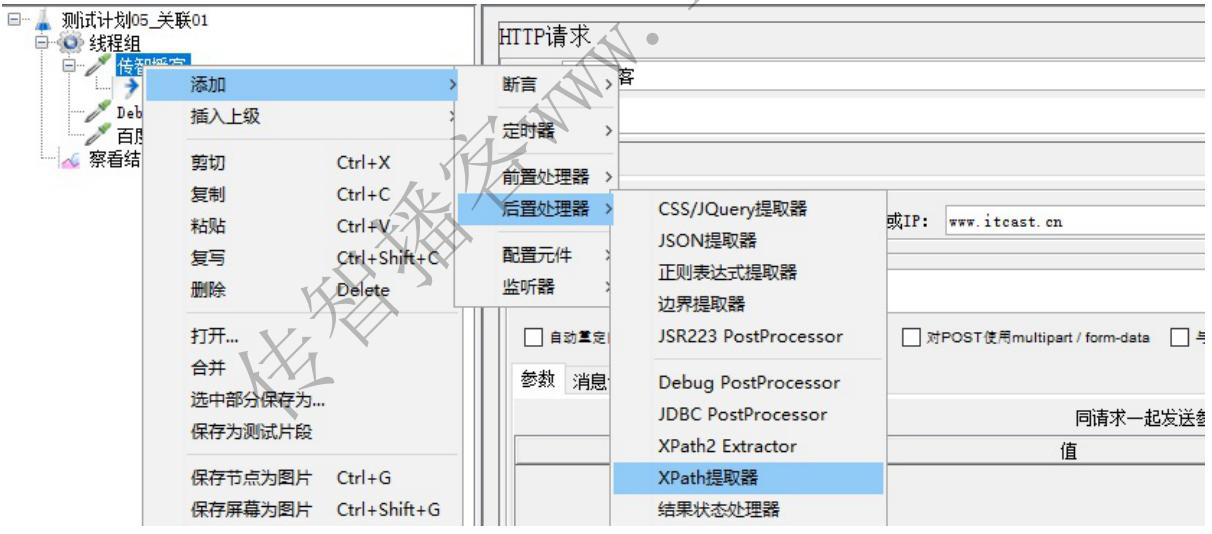
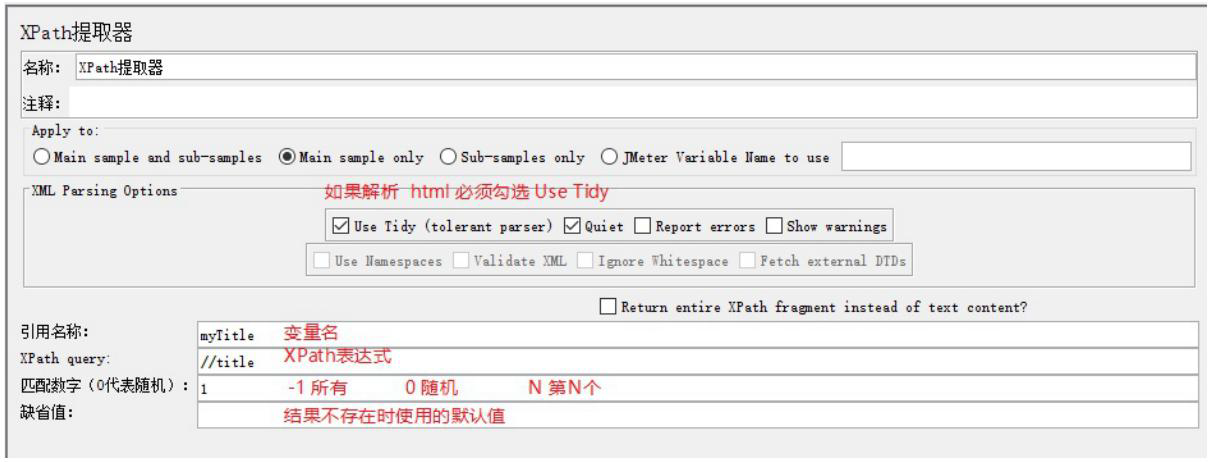
提取title标签内容,如果请求成功,就会把title标签中的内容放到myTitle变量中
关联-正则表达式提取器
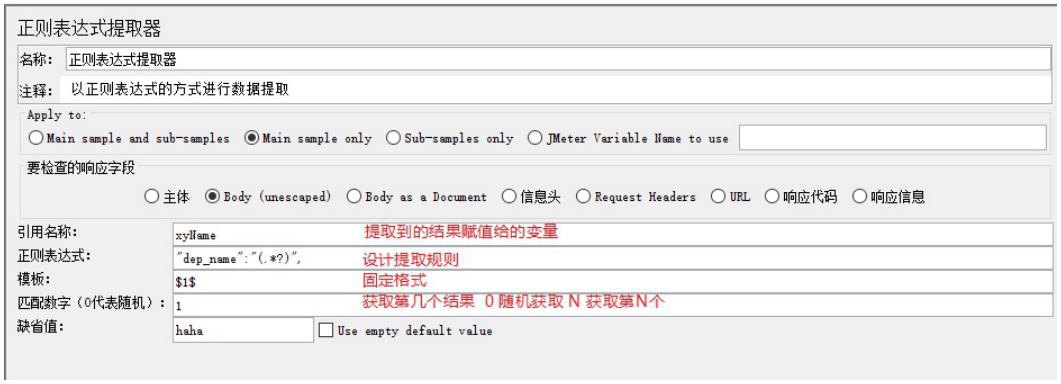
需求:两个请求,请时求A查询所有学院信息,请求B访问百度,从请求A中提取出第一个学院的学院名称,把名称放在百度上搜索
步骤:
1、搭框架,编写两个请求,查询所有学院信息 + 百度搜索
2、核心:从学院查询中提取学院名称
3、传递给百度,调用格式: ${变量名}
建议: 如果从标签文档提取数据建议使用 XPath 提取器,如果从非标签文档提取数据建议使用正则表达式提取器
跨线程组关联
变量作用域局限于当前线程组,其他线程组不可以直接调用。可以将请求A中提取的结果导出到公共空间(可以被不同线程组共享),请求B再从公开空间调用该变量,相当于全局变量。
步骤:
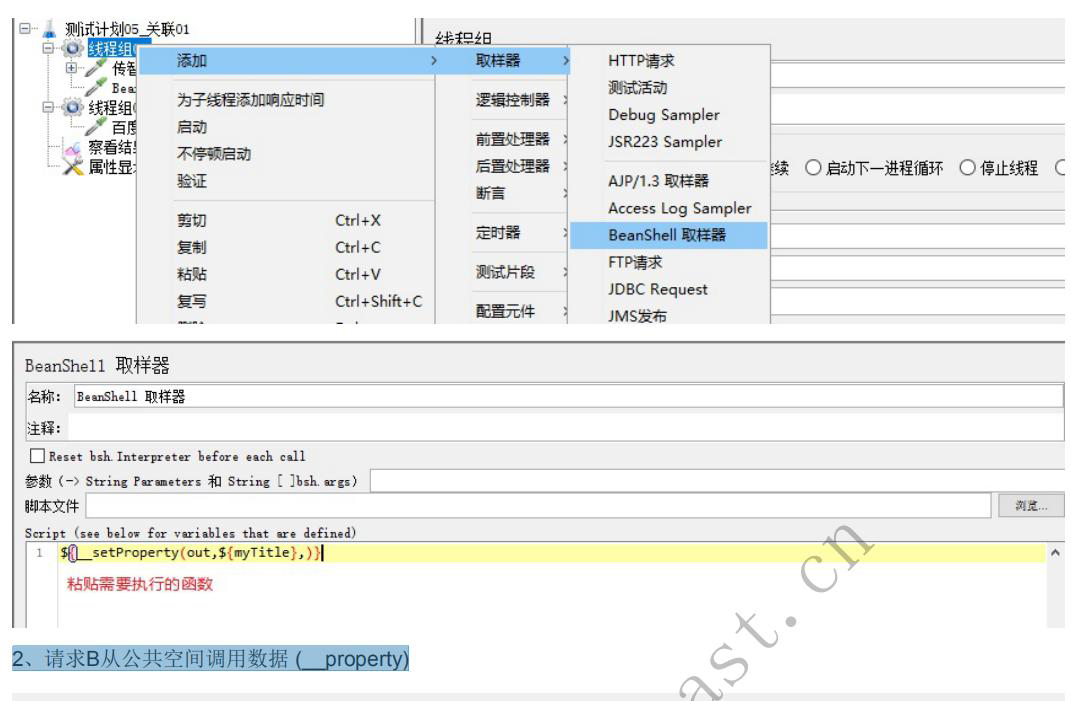
1、将请求A的数据导出到公共空间( _setProperty)
2、把代码放在beanshell取样器中
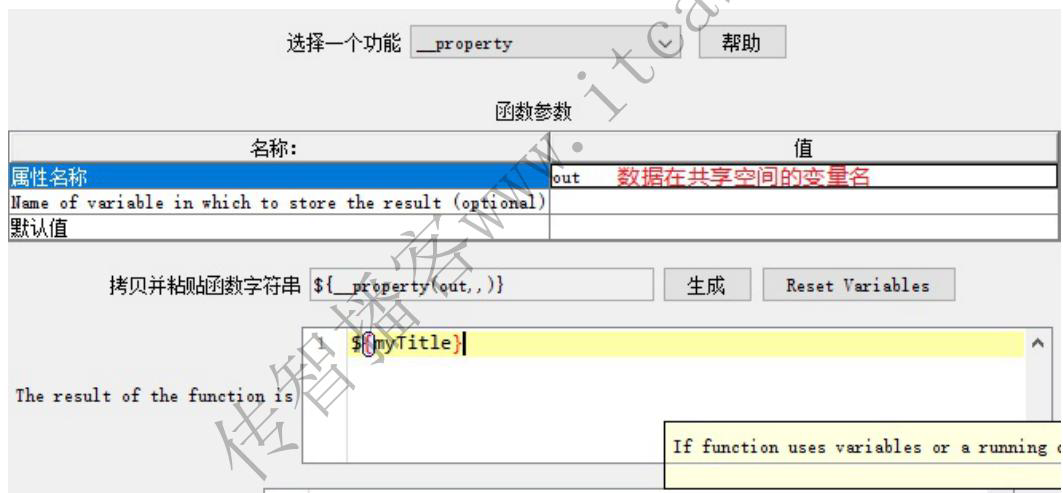
3、请求B从公共空间调用数据 (__property)
选择函数助手
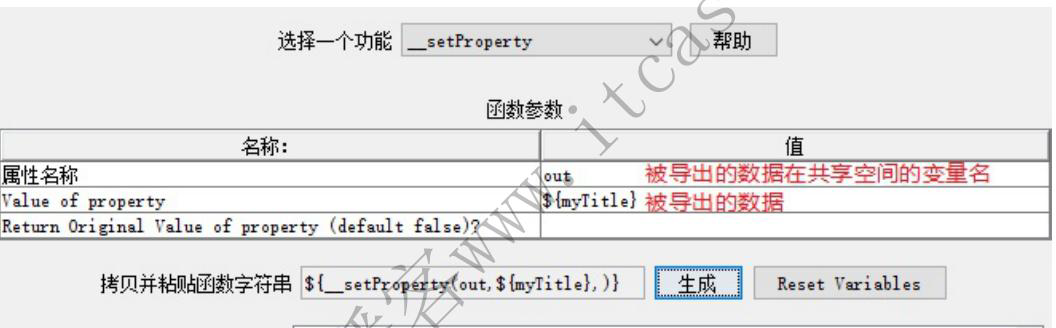
放
拿
性能测试
模拟各种正常的、峰值的测试环境,检测程序的各项性能指标是否能够达标 更
高并发
JMeter 中内置了 定时器,可以实现时间模式相关的性能测试
需求1:同一时刻 100 个同学去访问学生管理系统的查询所有学院信息功能,统计高并发情况下平均响应时间以及错误率(高并发)
1、搭框架,测试计划,线程组,取样器,结果树(局限性),指定线程组的线程数属性值为 100
2、添加定时器 synchronizing timer(集合点组件)
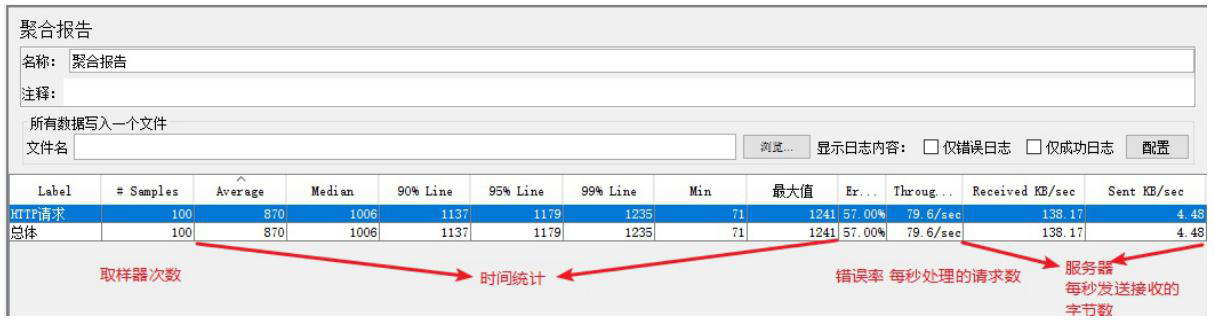
3、运行并查看结果查看:聚合报告组件,可以对结果汇总分析
同步定时器
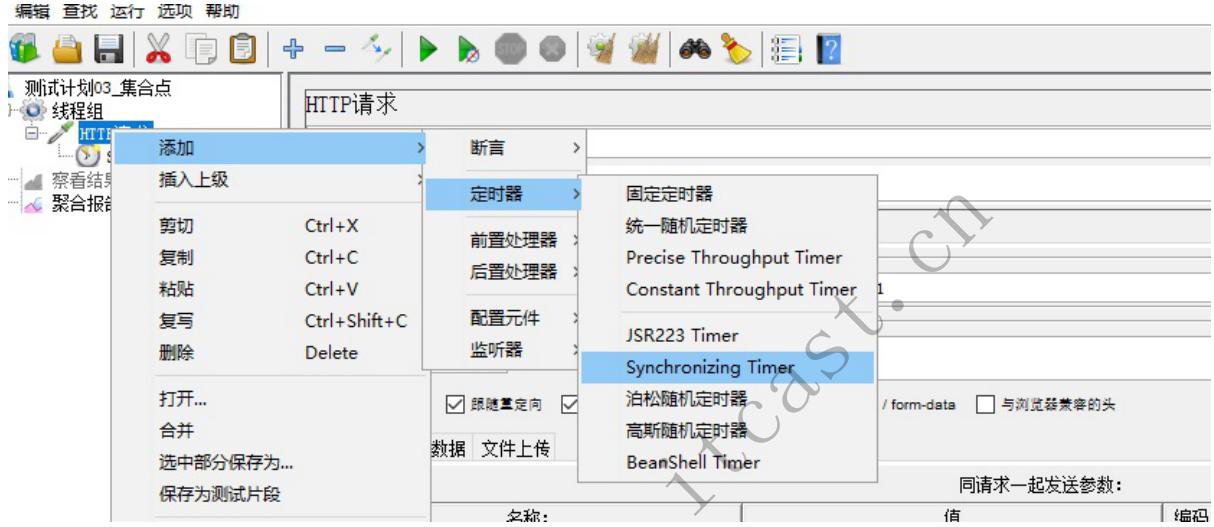

超时时间必须要设置,防止出现死等状态
将结果树监听器替换成聚合报告
高频率
需求2:一个用户以 20QPS ( == 20 次/s) 的频率访问学生管理系统服务器,持续15秒,统计服务器的平均响应时间
QPS: Query per Seconds 每秒查询数(查询率),每秒访问多少次服务器
1、搭框架,测试计划,线程组,取样器,聚合报告,根据题干计算数据:
循环次数 = 访问频率 * 持续时间
2、添加QPS访问频率控制的相关组件:
每分钟访问次数 = 访问频率 * 60
设置常量吞吐量定时器
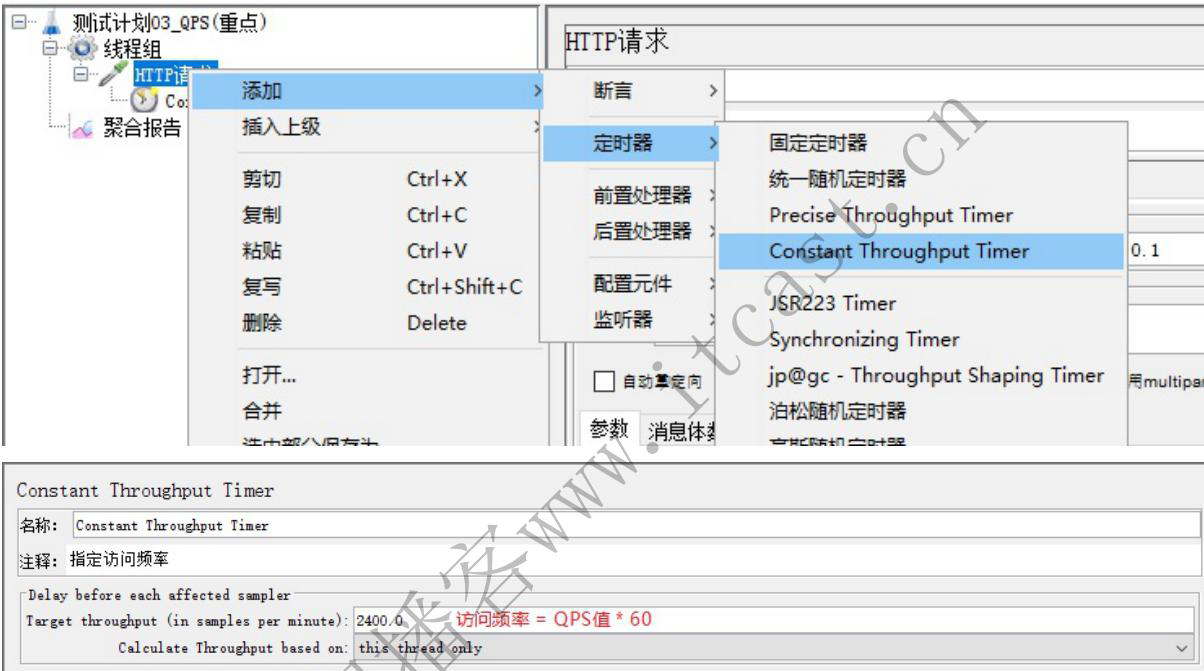
设置循环次数,频率*时间 (20qps * 15s=300次)
分布式
多台机协作,以集群的方式完成测试任务,可以提高测试效率。
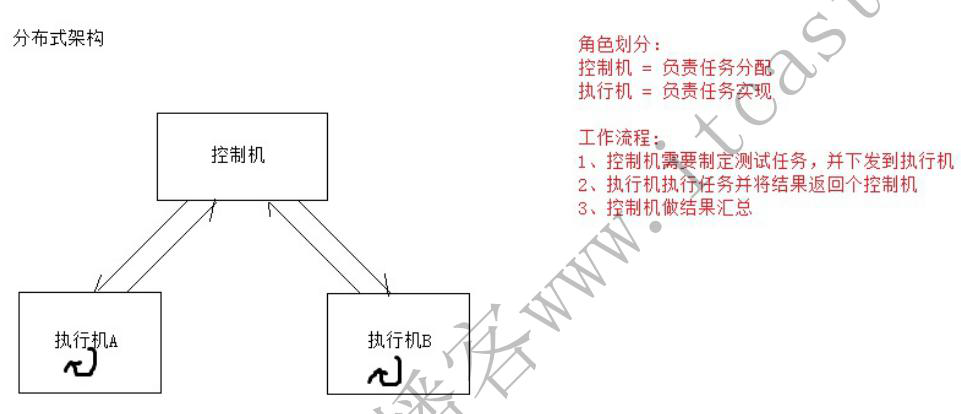
环境搭建:
1、不同的测试机上安装 Jmeter
2、配置基础环境(统一操作系统、JDK、Jmeter …. )
3、核心: 控制机如何与执行机通信? 关键点:端口号
4、控制机中设置执行机的 IP
%JMETER_HOME%/bin/jmeter.properties —-> remote_hosts=执行机A的IP:端口号, 执行机B的IP:端口号, …..

3-3、控制机和执行机都得设置远程访问相关属性:
server.rmi.ssl.disable=true
